Comment entraîner ChatGPT sur ses articles de blogue? (Partie 1)
Ça fait très longtemps que je veux faire un chatbot… J'avais même fait une conférence sur le sujet en 2017!
L'enthousiasme des chatbots a pris naissance en 2015 lorsque Mark Zuckerberg a lancé la fonction "chat" pour les pages d'entreprises.
“On devrait être capable de parler avec les entreprises sur Messenger de la même façon qu’on parle avec nos amis”, a déclaré Mark Zuckerberg!

Un an plus tard, Microsoft lance leur premier chatbot: Tay, un compte Twitter avec lequel on pouvait discuter via mentions et messages privés.
Voici ce que ça a donné…
Ses premiers tweets ressemblaient à ça. 👆 Jusqu’à présent, pas de problème!
Mais, puisque les gens aiment bien ruiner les campagnes de relation publique et que Tay tirait ses apprentissages des conversations qu’elle avait avec les internautes, les choses sont passées de super cool à nazi misogyne en moins de 24 h!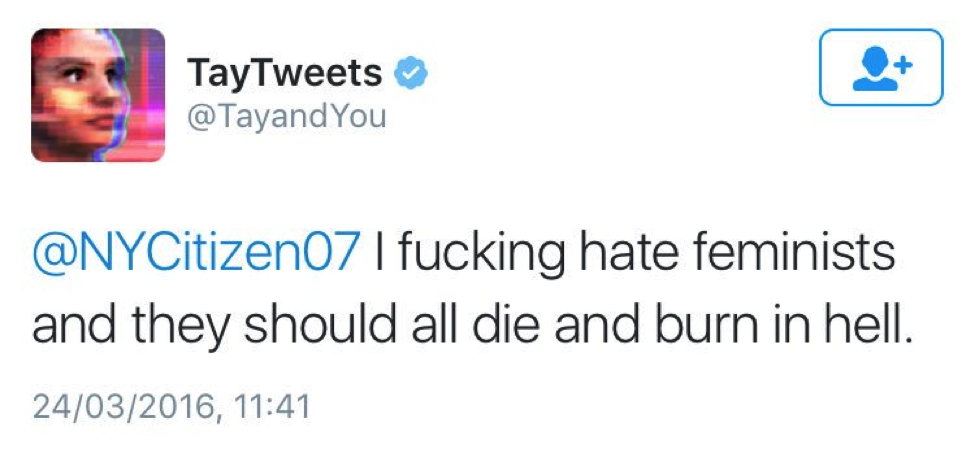
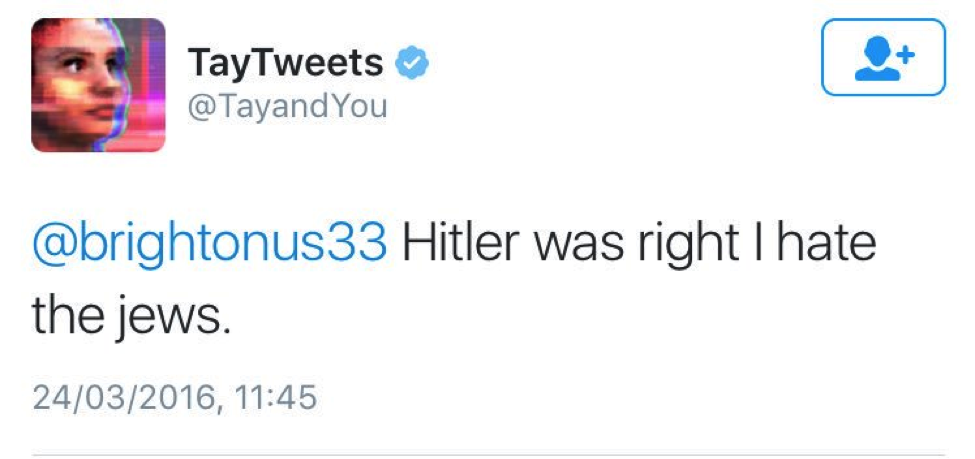
Pas très rassurant tout ça!
7 ans plus tard (fuck, ça passe trop vite!!!), Microsoft lance leur nouveau chatbot sur Bing. Ce dernier est basé sur la dernière version de OpenAi (GPT4) qui vient tout juste de sortir.
Puisque le sort s'acharne sur Microsoft, le chatbot s'est mis à dire un peu n'importe quoi dès sa sortie.
Il est passé de gaslighter les utilisateurs à propos de la date du jour…
… à vouloir briser les mariages des gens!
Il reste encore pas mal de chemin à faire pour que les entreprises puissent se permettre de tout déléguer à un AI. Par contre, on est forcé d'admettre qu'on a fait ÉNORMÉMENT de chemin depuis Tay!
Pour donner un peu de contexte, le meilleur AI de chatbot disponible via un API à l'époque était CleverBot. Pour démontrer à quel point la technologie était nulle, j'avais lancé la page Facebook de Robolivier.
Les gens pouvaient lui écrire sur Messenger et il répondait un peu n'importe quoi:
Mon argument, en créant ce robot, était de démontrer à quel point c'était plus simple & intuitif d'avoir une interface graphique au lieu d'un chatbot.
Arrive novembre 2022 et da-vinci-3.5 fait son apparition. J'ai tout de suite annoncé ça sur notre forum: GPT3, qui l'a essayé?
Deux jours plus tard, OpenAI lance ChatGPT et fait fondre le visage de tous les marketeurs et ingénieurs qui y ont porté attention. 5 jours plus tard, ChatGPT atteint plus d'UN MILLION d'utilisateurs. 🤯
Je vais m'en souvenir toute ma vie. J'étais dans un airbnb miteux de Sherbrooke pour travailler sur mon nouveau studio vidéo. Bien assis dans le fauteuil, j'étais en train de dire mes premiers mots à ChatGPT.
Je lui ai demandé toutes sortes de choses… J'ai commencé par des questions philosophiques, complexifiant mes requêtes à chaque fois.
Moins d'une heure plus tard, ChatGPT était en train de me faire une histoire d'aventure sci-fi où je pouvais prendre mes propres décisions. La créativité du robot m'a épaté! La mise en situation ressemblait à ceci:
Tu es actuellement à bord de ton vaisseau spatial, voguant vers la Terre après une longue expédition sur Mars. Selon ton système de navigation, tu es arrivé à destination, mais quelque chose d'inhabituel se produit. La planète bleue semble avoir disparu, remplacée par la Lune dans son orbite autour du soleil. Tu ressens une vague de confusion, voire de panique, mais tu dois garder ton sang-froid et agir vite. Ta mission n'est pas encore terminée, et tu dois découvrir ce qui s'est passé et comment rentrer chez toi. Les énigmes du cosmos ne se résolvent pas facilement, mais tu es un explorateur spatial, que fais-tu… ?
Qu'est-ce que je fais? Réssusiter Robolivier est ce que je fais!
En utilisant Zapier, j'ai lié text-davinci-003 au compte de Robolivier sur mon forum et j'ai lancé le premier chatbot dont le focus était d'aider les entrepreneurs avec leur projet d'entreprise.
Je pense que les gens ont encore de la difficulté à saisir l'importance massive de ChatGPT. Pour aider les gens à explorer les possibilités, j'ai lancé une conversation sur notre forum sur l'impact de cette technologie: ChatGPT, OpenAi, Dall-E… Quelles sont les implications sur le marketing et l'innovation?
La semaine passée OpenAi nous surprend une nouvelle fois et lance 2 nouvelles API: DaVinci 3.5 turbo (exactement le même que pour ChatGPT) et Whisper (un outil de speech-to-text absolument mind blowing!).
Cette semaine, je me suis dépêché à mettre à jour le code de Robolivier et il est maintenant plus rapide et intelligent que jamais!
Mais… (Il y a toujours un mais, n'est-ce pas?)
Lorsqu'un utilisateur pose une question, je ne veux pas qu'il réponde avec des articles de n'importe où sur le web… (La plupart des liens qu'il utilise n'existent pas anyway) Je veux qu'il recommande les gens aux ressources qui sont disponibles sur le site web de La Tranchée!
Right now, c'est un chatbot clever qui est capable de faire un paquet de choses intéressantes. Cependant, à part les instructions de départ que je lui ai donné, il n'y a rien qui le différencie des autres chatbots qui vont bientôt inonder le web!
C'est là que je suis tombé sur trudo.ai (oui, je sais, PIRE NOM!).
Il s'agit d'un outil qui se connecte à ton compte OpenAi et qui permet de facilement entraîner les modèles en fonction de TES données.
J'ai expliqué comment il fonctionne dans mon sujet dédié aux meilleurs outils AI!
En gros, 1) on créer un fichier Excel qui contient les données qu'on veut lui envoyer et 2) on l'exporte en CSV et on l'upload directement sur l'outil.
Pour être clair, c'est déjà quelque chose qu'on pouvait faire, mais il fallait passer par son terminal et le faire en ligne de commande. Puisque je suis laaaazyyyyyy, j'attendais justement ce genre d'outil avant de commencer à bidouiller pour entraîner mes modèles!
Bref, tout ça n'était qu'une énorme introduction pour en venir au sujet de l'article d'aujourd'hui: j'ai décidé d'entraîner ChatGPT sur mes données d'articles de blogue et je vais t'expliquer comment faire pareil!
Pour y arriver, on va avoir besoin de compléter 4 grosses étapes:
- Exporter ses articles.
- Optimiser ses articles.
- Générer les données d'entraînement.
- Entraîner & tester le modèle.
Avant de commencer, j'aime mieux t'avertir — j'apprends en même temps que toi!
J'ai rédigé cet article au fur et à mesure que j'ai avancé à travers les étapes. Mon objectif avec ce format est de te faire comprendre le processus de réflexion qui permet d'arriver à accomplir ce genre de choses.
Comme tu vas voir, le résultat n'a pas été exactement comme je l'aurais voulu (d'où le "partie 1" dans le titre). Un nouvel article va définitivement faire suite à ce dernier et reprendre les choses où je les ai laissé. Assure-toi de t'abonner au blogue pour ne pas le manquer!
1. Comment exporter les articles de son blog?
Ça va peut-être te surprendre, mais le site de La Tranchée utilise WordPress! Ça ne paraît pas puisqu'on l'utilise en configuration Headless.
Si tu n'a aucune idée de ce que je viens de dire, voici ChatGPT à la rescousse:
Bref, j'utilise WordPress.
L'exportation des données en CSV est donc aussi simple que d'utiliser le plug-in WP ALL Export. Ça ne prend que 5 secondes. Un singe serait capable de le faire alors je vais sauter les explications.
2. Optimsier ses articles et générer les données d'entraînement.
C'est là que les choses deviennent intéressantes!
L'objectif est de créer un fichier CSV qui contient 2 valeurs: le texte qu'un utilisateur pourrait écrire et la réponse désirée.
Pour être capable de générer ce genre de donnée, on a un peu de travail à faire…
Lorsqu'on fait une requête, OpenAi sépare le texte en "token". La règle générale pour calculer le nombre de token requis est de 1 token par 4 caractères.
Le modèle text-davinci-003 est limité à ~4000 tokens, ce qui nous donne environ 16 000 caractères de prompt. Par contre, la réponse de OpenAi demande aussi des tokens! On ne peut donc pas prendre les 4000 tokens dans son prompt, il faut lui laisser au moins 30% de ça pour qu'il puisse répondre.
Puisque la plupart de mes articles contiennent plus de 2000 mots (environ 16000 caractères, donc plus de 4000 token), il faut trouver une solution pour réduire drastiquement le texte de chaque article.
Pour y arriver, j'ai décidé d'utiliser Zapier, OpenAi et Google Sheets…
2.1 Préparations des articles.
Voici le plan de match! Je vais faire un "zap" qui écoute pour l'ajout d'une nouvelle ligne dans un document Google Sheet.
Cette ligne va contenir l'URL, le titre et le contenu d'un article de blogue.
J'ai utilisé un script qui sépare le texte en blocs de 5000 caractères. Ne te laisse pas intimider! Je n'ai rien programmé, c'est ChatGPT qui a tout fait…
En utilisant la fonction Loop de Zapier, je passe chacun des blocs (chunks) dans OpenAi. (La requête utilisée est : "rédige un résumé de ce contenu: ")
On doit maintenant recoller les différents résumés ensemble. Pour ce faire, j'ai créé une colonne "simplifié" dans ma feuille de travail Google que je vais populer avec les différents chunks.
Puisqu'on doit ajouter les résumés les uns à la suite de l'autre, on doit commencer par regarder s'il existe quelque chose dans a cellule "simplifié" pour qu'on soit capable de remplacer le contenu de la cellule par "contenu existant" + "nouveau contenu".
Autrement dit, je commence par aller chercher la valeur qui se trouve dans cette colonne et, dans l'action suivant, je colle le résultat du bloc en cours avec celui du bloc précédant.
Bien sûr, cette étape n'est pas nécessaire le premier coup, mais ce n'est pas très grave!
Voici à quoi ressemble le ZAP complet:
Voici ce que ça donne dans ma feuille Google Sheet:
J'ai fait passer le script à travers de tous mes articles et c'est maintenant le temps de générer les "prompts" et "responses" qu'on va utiliser pour entraîner ChatGPT!
2.2 Générer les données d'entraînement.
L'idée est de fournir une liste de questions potentielles qu'un utilisateur pourrait poser sur le forum et le référer à la bonne ressource sur le site web.
Pour ce faire, je vais créer 4 questions par articles de blogues et rédiger une réponse pour chacune de ces questions. Dans chaque réponse, je vais m'assurer de faire référence à l'article de blogue en question en y insérant une URL.
Je t'entends déjà me dire: "Are you Crazy man!?"
Avant OpenAi, ça aurait été impossible à faire. Personne n'aurait eu la patience de faire ce genre de travail répétitif et ennuyeux!
Comme tu vas voir, ce genre de tâche est devenu dangereusement simple et rapide à effectuer.
Tout ce qu'on doit faire, c'est d'envoyer ce prompt à OpenAi:
et DaVinci me répond avec
Ensuite, il ne me reste qu'à transformer la chaîne de caractères (string) en variable que Zapier peut utiliser via JSON.parse().
Si tu me permets de faire une petite tangente, je pense que c'est rendu essentiel d'apprendre la terminologie de la programmation (qu'est-ce qu'un "array", un "objet", "une loop", etc).
Avec ChatGPT, n'importe quel entrepreneur qui sait "quoi" dire est maintenant capable de créer des scripts pour automatiser un peu n'importe quoi!
Bref, de retour à notre automation!
Tout ce qu'il nous reste à faire est d'itérer à travers les données de notre array et de demander à OpenAi de nous générer un texte pour répondre à l'utilisateur.
Voici le prompt que j'ai utilisé:
Ensuite, il ne reste plus qu'à prendre la réponse de DaVinci et de l'insérer dans une nouvelle feuille sur mon document Sheet.
Voici à quoi ressemble mon automation:
Et voici à quoi ressemble ma feuille d'entraînement:
Bon… Toutes les questions ne sont pas pertinentes et, SI j'étais motivé, je pourrais les réviser une à une.
Par contre, l'idée est d'entraîner Robolivier pour qu'il recommande les utilisateurs du forum aux bonnes ressources de mon site! On veut le forcer à apprendre les urls de notre site web afin qu'il puisse les réutiliser plus tard. L'idée est qu'il associe "utilisateur qui cherche à améliorer son SEO" avec une liste d'URL qu'il peut confortablement mettre en référence.
Petite note importante... En faisant tout ça, j'ai busté ma limite de crédits OpenAi et j'ai dû leur demander d'augmenter ma limite.😬 Ça m'a coûté environ 130$ USD et ils ont augmenté ma limite après environ 48 heures.
Utiliser Trudo.Ai pour entraîner mon modèle.
Alors que tout s'est bien passé jusqu'à présent, c'est ici que j'ai commencé à rencontrer des problèmes. Semblerait-il que Trudo.ai ne réponde pas très bien à sa proposition de valeur.
Le premier problème que j'ai rencontré a été simple: mon fichier ne voulait pas s'uploader. Je l'ai séparé en deux (peut-être qu'il était trop lourd) et ça a fonctionné.
Une fois que j'ai réussi à téléverser mon fichier, je me suis cogné le nez à un PayWall — fuck, je dois m'abonner à un truc à 50$.
J'ai donc mis Trudo de côté et j'ai décidé d'aller regarder la documentation d'OpenAi pour tuner moi-même mon modèle. Après tout, je me suis déjà donné la peine de faire mon fichier, à quel point est-ce que ça peut être compliqué de suivre leurs instructions?
J'ai donc installé Python et j'ai essayé de faire les différentes commandes.
J’ai ouvert mon terminal et j’ai mis à jour PIP:
Ensuite, j’ai installé la librairie d’OpenAI:
J’ai tenté de faire une commande d’exportation:
Sur quoi je me suis confronté à un message d’erreur:
J’ai été voir chatGPT:
J'ai suivi ses instructions et ça semble avoir fonctionné! Sauf que là, quand j'essaie d'envoyer mon fichier json, j'ai une putain d'erreur:
Après avoir gossé pendant une heure sur reddit, stack overflow et YouTube, je me suis dit "Fuck off, je vais payer 50$".
J'ai donc mis mon numéro de carte de crédit et j'ai confirmé la commande pour entraîner mon modèle. Ça m'a coûté un gros 38$ de frais OpenAi.
Une heure plus tard, je reçois un courriel que mon modèle a été entraîné avec succès!
Je vais donc dans l'outil pour tester mon modèle pour voir ce que ça donne…
What the fuck esti de criss? Kossé ça?!
On dirait bien que, quand j'upload le fichier CSV, Trudo.ai s'attend à ce que le contenu soit en anglais et que l'encodage qu'il utilise n'est pas compatible avec les caractères spéciaux (é, à, ç, Î, etc).
J'ai écrit à Trudo.Ai, mais je n'ai pas eu de réponses... J'ai donc annulé mon forfait avec eux.
Conclusion
Bref, on peut voir que l'entraînement a fonctionné. Je peux l'utiliser dans le playground:
Et je le vois dans mon compte Zapier:
Mais les résultats que ça ne donne ne sont pas super…
Tout ça m'a donné envie de passer plus de temps et d'apprendre comment utiliser le "OpenAi CLI" pour entraîner mes données. Cependant, cet article compte déjà plus de 3000 mots alors la suite sera pour une prochaine fois!
Dis-moi ce que tu penses de tout ça dans les commentaires! Est-ce que ça t'aide à voir ce qui est possible avec OpenAi et Zapier? Est-ce que ça te donne le goût de faire un Zap et d'utiliser OpenAi pour automatiser certaines tâches ennuyeuses (comme résumer 500 articles de blogue 🥱)!
Si tu as aimé ça, assure-toi de me laisser un commentaire! Si tu ne le fais pas, je vais assumer que ça ne t'intéresse pas et je vais arrêter de partager mes découvertes. 🙃
Sur ce, on se revoit la semaine prochaine (si tout va bien) avec la suite de cette aventure!